
What is an AI accelerator?
The need for AI inference at the edge has rapidly changed the dynamics of artificial intelligence and machine learning algorithms that can be deployed on the hardware. The spark of developing specialized hardware for AI workloads has been growing exponentially in the last decade to deal with the complex AI tasks that can be data-intensive. In general, AI accelerators are computer hardware that has a dedicated processor designed to accelerate machine learning computations.
Implementing AI algorithms executed in software on CPUs and computer hardware require more power making them impractical for many of the AI inference applications. To solve this bottleneck and improve the performance along with latency comes the AI accelerators. But before adding specialized AI chips to any hardware there are a lot of efforts put into developing architectural elements and technologies. Some of the well-known research chips for their performance and power are the NeuFlow chip, TETRIS, MIT Eyeriss chip, and the TrueNorth.
The chips are designed in accordance with the intended application which can be low-power applications, embedded chips and systems, autonomous systems, data center chips, and cards. There are several manufacturers that have come up with AI accelerators based on different architectures from ARM to RISC-V. Few of the low-power chips include the TPU Edge processor, Rockchip RK3399Pro, Mythic Intelligent Processing Unit accelerator, and the latest Syntiant's NDP200. You can find a detailed survey on the machine learning hardware accelerators in this research paper.
What is a software AI accelerator?
As the name suggests, software AI accelerators are designed to bring in fine AI performance improvements through software optimizations that can make platforms up to 100x faster. Depending on the requirements and type of application, the need for AI acceleration at the edge or at the cloud can vary. To make it a seamless journey for any developer, there has to be a well-developed end-to-end AI software ecosystem.

(Image Credit: VentureBeat)
To understand the utilization of software AI accelerators, there are several operations that can be faster if done using AI/ML algorithms, like object detection, face recognition, and even text identification. Cloud services applications and other digital content creation companies have started to use these software optimizations to improve performance and efficiency, reducing the cost by millions of dollars. There are have massive developments in software AI acceleration as it can improve the performance by 10-1000x and the data parameters in the AI and machine learning models have been increasing at a very high rate. Around three years back, a natural language AI model, ELMo had 94 million parameters which have grown to over 1 trillion parameters in this year.
Recently, Intel showcased how software AI accelerators are capable of delivering orders of magnitude performance gain for AI across deep learning, classical machine learning, and graph analytics.
Types of hardware AI accelerators
AI-optimized hardware can be classified into various categories. Any AI or machine learning model that can be trained on GPU can be considered as AI accelerated GPUs. GPUs have got faster than ever before and are capable to speed up deep learning training. NVIDIA has released more information on their latest training and inference benchmarks for popular models. However, AI accelerated hardware has been introduced in many computer-related hardware.
When it comes to the application-specific integrated circuits, these are very different from GPU accelerated hardware as ASICs are tailor-made for specific AI functions. Due to its custom made and application-specific, this hardware is expensive to develop and produce, however, they outperform other general-purpose AI hardware. Amazon’s AWS Inferentia machine learning processor is application-specific integrated hardware for specialized inference workloads. AWS Inferentia was built to give high inference performance at the lowest cost in the cloud. Irrespective of several factors, AWS Inferentia can deliver higher throughput at target latency and at a lower cost compared to GPUs and CPUs.
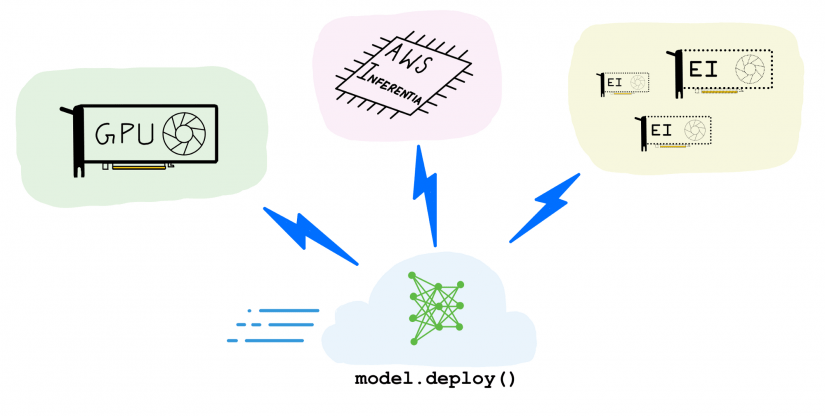
(Image Credit: towards data science)
We have also seen Google’s application-specific integrated hardware, Edge TPU, which is designed to run AI inference at the edge. It delivers high performance in a small physical footprint, enabling the deployment of high-accuracy AI at the edge. The end-to-end AI infrastructure facilitates the deployment of AI-based solutions. This type of tensor processor unit-based AI accelerators uses predictive models such as artificial neural networks (ANNs) or random forests (RFs).
Speaking about field-programmable gate arrays (FPGAs), they are deployed in the data centers for machine learning inference. FPGAs are basic programmable logic blocks that increase flexibility when compared to any GPU accelerated hardware.
How to choose the right AI accelerator?
Not all AI accelerated hardware are best for every AI-based application. So, there are several factors that need to be considered before choosing the right AI accelerator for your application and requirements. One of the key parameters is the model type and programmability, wherein the customer needs to analyze and review what kind of model size, custom operators, and supported frameworks are required for the application. The programmability can come into the picture when there is a need for fully programmable hardware (CPUs) or a closed system with a fixed set of supported operations like in the ASIC.

(Image Credit: towards data science)
The next factor to think about is the target throughput, latency, and cost which also includes the price/performance ratio. Application-specific integrated circuit AWS Inferentia delivers a lower price/performance ratio and improved latency when compared to the general-purpose processors. But there is another crucial factor in choosing the right AI accelerator is the compiler and runtime toolchain and ease of use.
Final thoughts
The future of AI accelerated hardware depends on the type of application we would be looking at in the next couple of decades. However, the advantage of energy efficiency, scalability, heterogeneous architecture, latency, and computational speed makes it the best option for any AI application rather than choosing a general-purpose development board. There is a lot of data-intensive workloads in the IoT and electronics domain that require AI acceleration through this specialized hardware. It will be interesting to see further developments and more efficient hardware in the near future.

Abhishek Jadhav is an engineering student, freelance tech writer, RISC-V Ambassador, and leader of the Open Hardware Developer Community.































Leave your feedback...