

Westworld Host Prototype

Made by 314Reactor / Artificial intelligence / Communication / Lights / Robotics / Voice
About the project
An OpenAI powered skull robot inspired from the robotics on the show Westworld
Project info
Difficulty: Difficult
Platforms: Raspberry Pi, Pimoroni
Estimated time: 4 hours
License: GNU General Public License, version 3 or later (GPL3+)
Items used in this project
Hardware components

View all
Story

Welcome to Westworld.
Genesis: The Birth of Consciousness
The purpose of this project is to create a robotic skull inspired by the blank host robots from the 2016 TV show, Westworld.
--Potential spoilers for the Westworld show ahead--
You can read more about Westworld and the hosts (robots) here. Essentially they are machines designed to be as human like as possible and assume roles within the violent theme park of Westworld. Before they are fully complete though they have a skeletal look; which is what this project is aiming for:
")
(It won't look as good as this.)
This project will be able to:
- Understand human speech
- Generate replies with AI
- Talk back with audio TTS
- Be in a skull format with the jaw able to move in response to the audio output
It will also help me evolve the framework that I created with one of my previous projects - Bot Engine and enable me to have a much more configurable AI system for future robotics projects.
Armature: Crafting the Vessel
Here are the basic parts for the skull:

The Pi Zero 2 W is of course the brain, the Inventor HAT mini is for operating the jaw servo and speaker. There is also a mini USB microphone and an adaptor for the Pi's USB Micro connector. I also put a heatsink on the Pi Zero 2 to try and keep it cool.
There is of course the skull that will hold all the tech; a standard skull model with moveable jaw from Amazon:

It's jaw is fully movable and is held in with a spring, I removed the spring and instead set the servo up to be able to move it, by attaching a nut and bolt to the servo:

Then putting a small bolt and nut through the bottom of the skull:
1 / 2
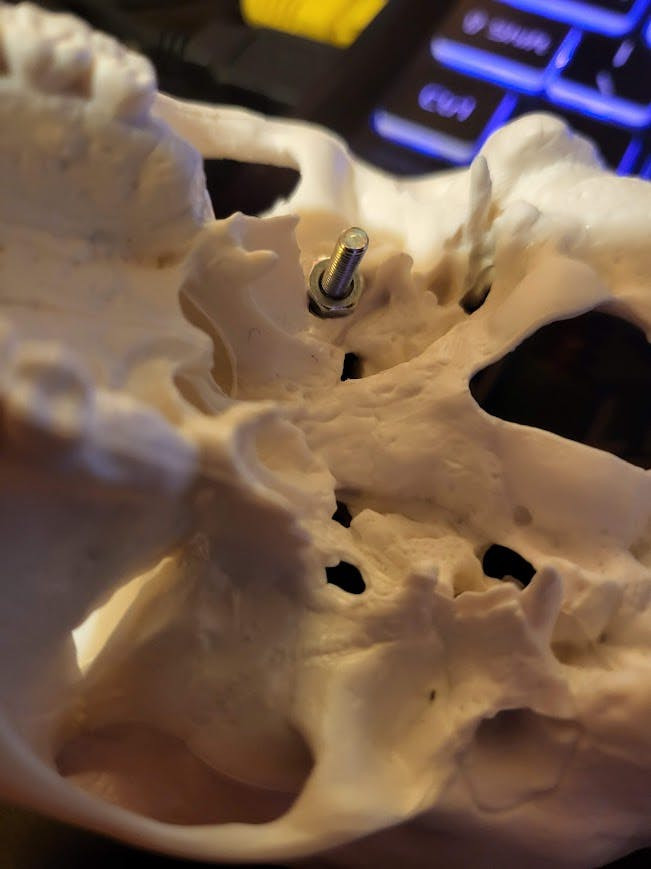
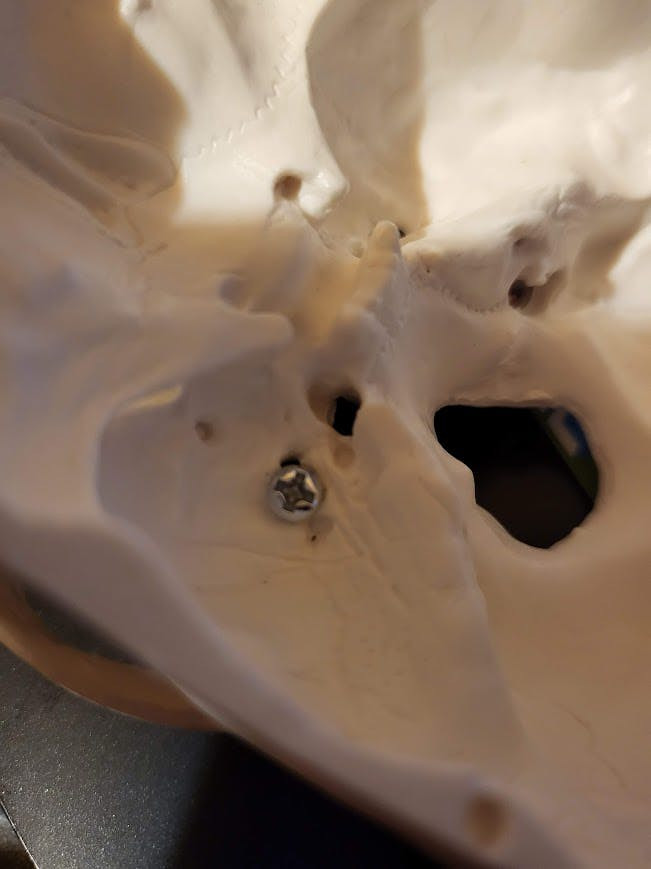
And then by gluing a wire crimp/connector to the bottom of the small bolt:

Then by screwing the bolt from the servo through the connector to hold it:

The finally gluing the jaw to the servo:

And then of course it was time to assemble up the HAT with the Pi, all instructions for the HAT can be found here:

This is of course for initial setup and programming. Eventually this will all sit within the skull:
1 / 3



I also took apart the USB mic to help it fit inside the skull:

However I found through testing that this had some odd effects on the audio, I am not sure why; maybe losing the shielding causes issues or I damaged the Mic. It was giving really bad audio quality and made the speech to text inoperable.
So I just managed to squeeze a full USB mic into the skull and that cleaned up the audio:

I also stuck the mini speaker onto the top of the skull, looped a USB cable through the bottom of the skull to hook it into the Pi for power and also put the servo wires through the bottom to reach the jaw servo.
And the cap of the skull just barely fits on:

The Maze: Programming the Mind
There are a number of modules that are pulled down alongside the main code with this repo:
cd ~
git clone --recursive https://github.com/LordofBone/WestworldPrototypeSkull.git
cd WestworldPrototypeSkullThey are ones that I have made:
- ChattingGPT
- EventHive
- Lakul
- And also Nix TTS by rendchevi.
ChattingGPT has integrations to use OpenAI's APIs to get ChatGPT based responses from inputs or it can run in offline mode and use Ollama to run a local LLM. It also allows a role to be set for the Chatbot, in this case; set to be a Westworld host.
EventHive is a priority-based, multithreaded event queue system in Python. It offers a robust solution for systems that handle different types of events, where certain events have higher priority over others. EventHive ensures that high-priority events are processed first and handles concurrent event producers and consumers in a thread-safe manner.
It basically allows this project to multi-task where possible and queue up tasks/events for responses and actions.
Lakul is a Speech to text system that can use OpenAI's Whisper locally or it can use the API to analyse audio files to perform speech to text functions.
Nix TTS is a nice little local running text to speech system that has a decent voice and runs relatively fast on a Pi Zero 2 W.
The full instructions for setting up the Pi software etc. is all contained under the GitHub README.md.
Once all setup a test suite can be run to ensure the main functions are working:
sudo python test_suite.pyThis will check the TTS, jaw movement, chatbot and STT functions are all working.
To test the overall even system and components are running there is a 'dry run' mode that will ensure all the events are being picked up and executed; but without running any actual functions.
sudo python activate.py --test_modeThis will loop through all the conversational functions without actioning them to ensure the core event engine works.
There is also a demo system that will kick off a short jaw movement and audio (can also be used with test mode):
sudo python activate.py --demo_modeTo start the main system and run all functions:
sudo python activate.pyThis instantiates the event queue and passes it into each constituent component, each being launched as a thread. It also kicks off the logging system controlled under:
utils/logging_system.pyI made this to ensure that the logging can be set and kept at a certain level, stopping other modules/libraries from changing the logging level or formatting (possibly still some bugs with this). Allowing for a consistent output of logs with each of the components and submodules.
Also, this all has to be run as a super user because the Inventor HAT requires it to utilise the rpi_ws281x package for the LEDs. So it would be best to use a fresh OS install and/or a virtual python env (detailed in the GitHub readme).
Each of the modules uses the event queue to consume events that will cause certain actions within them and also produce their own events to kick off other actions after they have run their own processes, for example:
def record_and_infer(self, event_type=None, event_data=None):
self.STT_handler.initiate_recording()
self.run_inference()
self.produce_event(ConversationDoneEvent(["CONVERSATION_ACTION_FINISHED"], 2))
return True
def get_event_handlers(self):
return {
"RECORD_INFER_SPEECH": self.record_and_infer,
}
def get_consumable_events(self):
return [STTEvent]This configures an event handler that listens for 'STTEvent' and when it consumes that event it checks the handler, if it receives 'RECORD_INFER_SPEECH' it kicks off the record and infer function. This allows for modular configuration of different components and allows them to all act concurrently with each other and respond to certain events. It's all pulled from EventHive, which has been designed to be as scalable, readable and maintainable as possible.
You can also see the produce event functionality as well there, which pushes an event into the queue for components downstream to pick up on.
Each component is kicked off with the main activation code:
event_queue = EventQueue(sleep_time=1)
systems = [
LedResourceMonitor(),
AudioDetector(event_queue, test_mode=test_mode),
TTSOperations(event_queue, test_mode=test_mode),
STTOperations(event_queue, test_mode=test_mode),
AudioJawSync(event_queue, test_mode=test_mode),
ChatbotOperations(event_queue, test_mode=test_mode),
CommandCheckOperations(event_queue, test_mode=test_mode),
PiOperations(event_queue, test_mode=test_mode),
ConversationEngine(event_queue, demo_mode=demo_mode),
]And has the event queue instantiation passed into them.
The modules themselves then init the superclass from EventHive and so have access to all of the queue consuming/pushing functions:
class STTOperations(EventActor):
def __init__(self, event_queue, test_mode=True):
super().__init__(event_queue)I will probably make a separate project at some point to go over EventHive specifically so keep an eye out for that.
When activated the bulk of the functionality revolves around the main conversation engine; this operates by utilising a loop to converse with the person interacting with it:
conversation_function_list = [
'generate_tts_bot_response',
'activate_jaw_audio',
'listen_stt',
'command_checker',
'get_bot_engine_response',
'scan_mode_on',
]Which is loaded into:
components/conversation_engine.pyWhen initialised it will load the into text that it will speak on boot, configured under:
config/tts_config.pyIt will then initiate scan mode where it waits to hear a noise to begin interactions (assuming it has heard a person), this detection is all controlled under:
components/audio_detector_runner.pyThis initiates the microphone using code from:
components/audio_system.pyThe audio system will setup the bitrates and frequency of the attached microphone as well as the audio out on the Inventor HAT Mini. Then using this mic initialisation the detector waits for an input to go over a configured amplitude threshold which is configured under:
config/audio_config.pyThis then sends an event into the queue to kick off the next part of the conversation engine, where the TTS is generated; the TTS being used is configured under:
config/tts_config.pyIt uses either a local TTS (pyttsx3/fakeyou/nix/openai) to get a wav file to play and saves it to:
audio/tts_output.wavOnce that's done it initiates the jaw movement system which is all controlled under:
components/jaw_system.pyWhich kicks off a thread to play the above wav file while also using the loopback device configured to get the amplitude of the audio in real-time from the wav and convert it into a pulse range for moving the servo; which makes the jaw open wider the louder the audio, giving the impression of it talking.
The loopback works nicely on RPi OS Bullseye, allowing it to take in audio like an internal microphone and analyse it, without have to use the real-world microphone. Hopefully newer versions of the OS allow for this modification as well. Here is the /etc/asound.conf that allows for this loopback at at the same time as outputting sound through the speakers:
# .asoundrc
pcm.multi {
type route;
slave.pcm {
type multi;
slaves.a.pcm "output";
slaves.b.pcm "loopin";
slaves.a.channels 2;
slaves.b.channels 2;
bindings.0.slave a;
bindings.0.channel 0;
bindings.1.slave a;
bindings.1.channel 1;
bindings.2.slave b;
bindings.2.channel 0;
bindings.3.slave b;
bindings.3.channel 1;
}
ttable.0.0 1;
ttable.1.1 1;
ttable.0.2 1;
ttable.1.3 1;
}
pcm.!default {
type plug
slave.pcm "multi"
}
pcm.output {
type hw
card 1
}
pcm.loopin {
type plug
slave.pcm "hw:Loopback,1,0"
}
pcm.loopout {
type plug
slave.pcm "hw:Loopback,0,0"
}This also uses the same audio controller mentioned above to play the audio and initialise the audio output. Again all setup for this is on the GitHub readme.
The hardware level servo controls are under:
hardware/jaw_controller.pyWhich utilises the hardware on the HAT to control the servo, the HAT controls are all under:
hardware/inventor_hat_controller.pyThis initialises the HAT and allows for the servo controls as well as the LEDs, which we will go over later.
Once it has spoken the text it then goes onto the speech to text function, this interfaces with Whisper local or via OpenAI's API by changing the offline_mode variable under:
components/stt_system.pyThis also uses the audio system to get input from the mic to create an audio file under:
audio/stt_recording.wavWhich is then passed onto the local model or the API for STT inferencing. This then pushes an event into the queue containing the inferenced speech.
Information on configuring the.env file required to add in API keys is found here in the readme.
The STT recording has parameters for silence threshold, silence timeout and maximum length of recording; this is to ensure that there is a maximum amount of audio it will record and stop after a certain amount of silence, so it should take in the words said by someone then when they have stopped talking, stop the recording (all configurable in the STT config file):
self.STT_handler.initiate_recording(max_seconds, silence_threshold, silence_duration)Next, the system checks for any commands by passing the output through:
components/command_system.pyThis checks for any configurable activation words which are all under:
config/command_config.pyWe will go over the command system later on.
If no commands are found it then moves onto getting the bot response with:
components/chatbot_system.pyWhich is all configured under:
config/chattinggpt_config.pyWhich allows a selection between ollama/openai and the role the bot is to take as well as whether it should use conversation history or not (this gives more context for every response, for a more consistent conversational experience).
When using Ollama for the bot response (offline mode) it uses the 'westworld-prototype' model that is created from the build script:
setup/build_llm.shWhich is built using the params under:
setup/ModelfileThis setup is all detailed in the GitHub README.md.
This Modelfile can also be configured to change the role/params of the chatbot, it is currently set to act as a Westworld host and also has a limit of 8 tokens as a response; to ensure that it does not take too long to generate on a Pi Zero 2 W's limited hardware.
Finally, with the chatbot response stored, it re-activates scan mode and waits for another noise from the human to continue the conversation engine loop. When a noise is detected it then generates the TTS of the bot response and speaks it, waits for human speech again and so on.
This enables a nice loop where the user can talk to the bot and it also ensures that the bot won't talk to itself or listen if no one is around, or at the very least mitigates that happening. It could do with some tweaking in future.
It also allows for the bot to be configured as a sort of 'sentry' where you could configure the amplitude threshold to a certain point, customise the TTS response and have it look out for anyone by listening for sounds of movement etc.
As a short interlude before we dive into the command system lets have a look at:
components/resource_monitor_leds.pyThis is launched as part of the activation code and hooks into psutil to get the CPU/RAM usage and represent this with the LEDs on the Inventor HAT mini, the more LEDs lit, the more % of ram is being used and colour of them represents the CPU usage (deep green for low usage and then a gradient up to deep red for as the usage approaches 100%), kind of like the Plumbob diamonds in The Sims:

This not only allows for diagnostic assistance when the skull cap is off but it also makes the internal circuits look like the inside of Data's head from Star Trek:
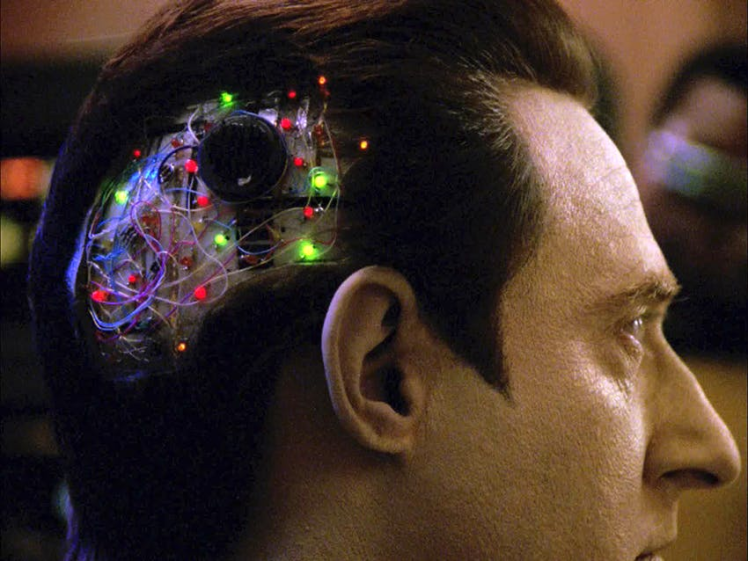
It also gives a cool look through the skull and eyes:
1 / 2


1 / 2


1 / 3



Really cool stuff. ChatGPT was a great help in creating that module.
So now we are going to look at the command system, under:
config/command_config.pyThere are 2 variables:
override_word = "freeze all motor functions"
de_override_word = "resume all motor functions"If the override word is picked up this will boot the conversation engine over to a separate loop from the conversation config file mentioned above:
command_function_list = [
'generate_tts_bot_response',
'activate_jaw_audio',
'execute_command',
'listen_stt',
'command_checker',
'scan_mode_on',
]This is very similar to the normal conversation function but of course has removed the entire chatbot response and just passes the STT outputs into the command executor, this works by checking the words being spoken and seeing if they match a list of configurable commands:
def process_command(self, event_data):
# Clean and normalize both input and comparison strings
clean_event_data = clean_text(event_data)
if clean_event_data == override_word:
self.event_producer(CommandCheckDoneEvent(["OVERRIDE_COMMAND_FOUND"], 1))
elif clean_event_data == de_override_word:
self.event_producer(CommandCheckDoneEvent(["DE_OVERRIDE_COMMAND_FOUND"], 1))
elif clean_event_data in ["SHUTDOWN", "SHUT DOWN", "shutdown", "shut down", "power off", "poweroff",
"turn off"]:
self.event_producer(CommandCheckDoneEvent(["COMMAND_FOUND", ["shutdown_command", shutdown_text]], 1))
logger.debug("Command checker finished, event output: SHUTDOWN")
elif clean_event_data in ["REBOOT", "restart", "reboot", "restart now", "reboot now"]:
self.event_producer(CommandCheckDoneEvent(["COMMAND_FOUND", ["reboot_command", reboot_text]], 1))
logger.debug("Command checker finished, event output: REBOOT")
elif clean_event_data in ["TEST", "test", "test command"]:
self.event_producer(CommandCheckDoneEvent(["COMMAND_FOUND", ["test_command", test_command_text]], 1))
logger.debug("Command checker finished, event output: TEST COMMAND")
else:
self.event_producer(CommandCheckDoneEvent(["COMMAND_FOUND", ["no_command", no_command_text]], 1))
logger.debug("Command checker finished, no commands detected")Which will then execute them, so at the moment this can be used to reboot or shutdown the skull by sending events to:
hardware/linux_command_controller.pyBut in future I intend to make this much more readable and expandable to allow for many more functions. This is of course to allow for lower-level control outside of the bots personality and also reflects what happens with the hosts in the show, when they are put into a debug/maintenance mode.
It will speak out what actions it is taking and then execute them, you can bring it out of this mode and back to normal conversation by saying the configurable de-override word. It will then return to the last thing it said and repeat that and await for human input again, back to the loop as if nothing happened.
In future iterations of this framework I will allow it to have control over the role the AI systems etc. to allow for full 'subconscious' control of the robot outside of its normal routine as well as being able to run diagnostics etc.
I mentioned earlier that the event queue system is meant to allow for concurrent operations to be run across different modules, this is fine for future functionality, say when the bot is talking but also processing something else, like an image from a camera. But there are certain times where a function will be reliant on the output from another module, such as the ChattingGPT system requiring an input from the speech to text system.
This is why the conversation engine has these function lists, and when each function has finished its set of actions it kicks off a completion event that then initiates the next function in the list:
self.produce_event(ConversationDoneEvent(["CONVERSATION_ACTION_FINISHED"], 1))This means you can configure a set of functions that are all meant to be executed consecutively while also being able to run concurrent actions alongside.
As mentioned I intend to use this project as a framework going forward, for instance; the next iteration of the Terminator Skull could be able to listen and process incoming audio for use in the chatbot system (sequential actions), while also analysing a human face and doing some internal processing on next actions to take, which would then be pushed into its event queue (concurrent actions).
As I iterate and improve on this it will become easier to expand upon and configure so that anyone can use this as an engine for creating their own robots. As the event queue system can be used to link up a huge number of systems without having to directly reference each others code, so under the hardware systems a module could be added that interacts with a full body robot for example. Alongside a configured chatbot role and commands, kind of like a 'shake and bake' robot framework.

With a powerful enough Pi (such as a Pi4/5 and beyond) the entire framework should be able to run locally as well, leveraging Ollama/Whisper/NixTTS to work completely offline; it will do this on a Pi Zero 2 W as well, but it operates quite slowly.
Also as a final touch I added a nice Delos wallpaper to the RPi OS GUI:
There are also some other miscellaneous things under the readme such as the rc.local file, which loads the file on boot:
setup/close_jaw.pyThis is because on boot the Inventor HAT sends a pulse to the servo, presumably to move it to its starting position (pulse = 0) which opens the jaw; so this script closes the jaw when the system has booted.
It's also a handy way of knowing when the OS has booted up and is ready to go.
Also you can use FakeYou for TTS, which can allow for any voice you want, this just needs to be enabled in the TTS config and requires your username/pass to be added to the.env file that is made as a part of setting up this project - details on the readme here.
Make sure to read the T&C's at FakeYou before signing up and don't do anything silly with it.
I take no responsibility for what anybody does with FakeYou via modifying this program, also be warned that ChatGPT may generate odd things to be passed into FakeYou, which also depends on what is said to ChatGPT, which also depends on what OpenAI's STT inferences your speech as - so I can't guarantee it won't generate weird things. Also bear in mind that using OpenAI's APIs will cost you money.
Reflections in the Mirror: Observing the Emergence
(Obviously all voices apart from mine in the above video are AI generated).
The above video was all run using the online APIs as this allows for much more speed, accuracy and better responses (I also found that the Pi can also end up trying to pull too much juice from a power supply not quite up to scratch and end up rebooting when inferencing stuff locally).
But with a beefy enough power supply the entire thing can run locally, it will just be quite slow on a Pi Zero 2 W (although not quite as horribly slow as I thought), the Ollama model is the smallest possible as larger models really can take a long time to generate responses. But even that generates decent responses, the smallest STT model also interprets speech correctly mostly and in a reasonable time.
The local TTS models can be a bit buggy, such as PyTTSx3 but Nix TTS works nicely and sounds natural, it just takes a little bit of time and processing to generate.
However the APIs are where it really shines, the speech to text is usually spot on the ChatGPT processing brings really good results, especially with conversational history enabled with ChattingGPT. And of course OpenAI's TTS is really natural sounding and has plenty of options - I just wish it was a bit louder, as the servo makes quite a bit of noise when moving along with the audio, the sound is also muffled a bit by the skull.
I was worried the microphone may have issues trying to hear through the skull, but it works perfectly.
One of the big issues is that the processing of the audio amplitude takes some time and so the jaw movements lag behind the actual speech - there could be some optimisations that could speed this up, but I also imagine that a faster Pi would handle this a lot better. When I load this up in a future project it will most likely be a larger form factor and thus allow me to use a Pi4/5 or even a Pi Zero 3 W when released. At the moment it just looks a bit goofy - but it's a good starting point to work forward from.
There are also times where the jaw system crashes out and won't move the jaw until the program is restarted - I need to figure out what causes this and add a test into the test suite to ensure this isn't happening any more, it seems to be relating to timings as when I put the logging into 'info' mode everything runs faster and this seems to crash things out, but in 'debug' mode it takes a little longer to print out all the logging which I think gives enough pause between actions to prevent whatever is causing these crashes.
I have edited the long waits out of the video as well as the tap noises I had to make to make it move to the next loop of the conversation (as it waits for a noise to indicate human presence before speaking out a reply, as mentioned above this is something that may need tweaking in future).
Overall though as seen in the video the bot is able to respond in some cool ways, taking into account the role that has been set with it and adjusting its responses accordingly. As Ollama and OpenAI's APIs don't support conversational history natively I have implemented this within ChattingGPT to allow the bot to keep track of the prior conversation; this all helps with the flow and consistency of the conversation.
One of the more bizarre things I found (I think this is a bug on OpenAI's end) is that sometimes the speech to text will return in Welsh, I think. It's very random and has happened a few times. Although it may be just the STT system not fully understanding what I am saying and selecting a different language, it has happened to others, such as this thread here.
Interestingly when it comes to some of the more philosophical and deep questions ChatGPT seems resilient to answer and sometimes even when being asked questions within the role of a Westworld host it will still refer to itself as a host rather than being the character; I think this is where the guardrails are kicking in and GPT 3.5 struggles with multiple layers of roles (it's essentially taking the role of a Westworld host and then within that role being asked to assume the role of a cowboy/bartender etc.).
However, with the right prompting it is able to assume a character, such as the bartender and is able to do some basic in-character interactions, however it can still fall back on some safety nets I think, for instance; when it won't make up and tell a story when requested. However the bartender role did interact with some of the more philosophical questions and stay in character, which was interesting.
With the right prompting, instructions and a few adjustments to the systems role I think this could produce some really interesting results, especially on GPT4. At the moment I am using gpt-3.5-turbo, so when 4 is available to me I will try some results on that.
The Ollama LLM can be a lot less restricted, however it takes a long time to generate responses and that's with the token limitation. If I was to get some beefier hardware and use a larger model such as LLAMA2 or the uncensored version along with the right prompting and a much larger token limit, I imagine the responses would be really scary.
Overall it's very cool to interact with the Westworld Prototype and you can almost get into a rhythm with it as it starts listening pretty much immediately after the jaw has closed after it has finished its sentence so you don't really have to wait for it to start listening, you can just talk as soon as it's finished its sentence.
I may tweak the loop in future though to remove the need to make noise before it communicates back. Something I will think about and experiment with to try and make it a bit more seamless, this would be vastly helped by having a camera on board for additional detection of its surroundings.
Also in the video you can see the glow in the eyes from the CPU/RAM LEDs which is really cool, as well as the glow through the cap of the skull - this adds another little layer of interaction and curiosity to the project. As well as giving some indication of what it's up to.
I had a few power outages also, I was using an Nvidia USB power supply and I assumed this would be enough, but it was still browning out if I had VNC running and using local STT/Ollama. The official Raspberry Pi power supply had no such issues though, I'm guessing the Pi Zero 2 W can drag a lot of amps down if it needs and was exceeding what the USB plug could do, or the USB cable I'm using isn't up to the task.
Beyond the Horizon: Contemplating the Future
So overall I am very happy with the progress made on this project, the number of integrations are nice and modular, utilising GitHub submodules ensuring that each constituent part can be updated on its own, making for easier scalability. I just need to move the TTS functions to their own project in GitHub and have them as a submodule now.
There are just a few bugs with the system, for instance the crashing randomly and some inconsistencies in how some of the components run with the event queue; so I will try and iron these out over time.
The jaw also has really jerky movements, so there may be a way to smooth these out over time, maybe using some sort of interpolation or smaller windows of measuring audio amplitude, however this would take some extra processing power. There may even be an easier way to measure the volume from the loopback and remove the complex processing, using that raw volume number to convert into the servo pulse range.
I will also look into any tweaks that can be made to free up RAM and power on the Pi Zero 2 W as it can really run out of RAM quickly and require a lot of swap. I think the cache gets erased as well when it's trying to utilise the locally running systems and then afterwards the system runs ultra slow.
As for power I think a decent supply is needed but I imagine there are some things I could switch off to help it along on a lesser supply.
The skull cap also doesn't sit fully flush which is a bit annoying, I may have to look into shaving just a bit of plastic off of the shroud for the USB mic to allow enough room for the circuitry to full fit in.
Also I need to make a better base for the skull at the moment I have a bit of blu-tack holding it but it can still fall over; so it needs a little bit of scaffolding around the servo to help it stand more stable.
I've learnt a lot working on this and greatly enhanced my previous Bot Engine tech; I can't wait to further scale it and implement it within a bigger robotics project using a Pi 5.
What do you think of the project? Let me know! Also feel free to make code suggestions or pull requests to the repo.
I'll see you all next time for another project...

One more loop.
Code
Credits
Related products















Leave your feedback...