

Small-footprint Keyword Spotting For Low-resource Languages

Made by shakhizat / Artificial intelligence / Home Automation / Robotics / Voice / IoT
About the project
Our project aims to develop an efficient system for detecting keywords in languages with limited resources on the Arduino Nicla Voice.
Project info
Difficulty: Difficult
Platforms: Arduino, Edge Impulse
Estimated time: 6 hours
License: GNU General Public License, version 3 or later (GPL3+)
Items used in this project

Story
In 2017, Google introduced the Speech Commands dataset, comprising 65, 000 one-second long utterances of 30 short words. This dataset primarily focuses on the English language, leaving a gap for low-resource languages like Kazakh. However, we can explore synthetic datasets as a potential solution. Synthetic datasets can be generated using various techniques, such as text-to-speech synthesis and data augmentation.
Our research institute, the Institute of Smart Systems and Artificial Intelligence, recently presented a research paper titled "Speech Command Recognition: Text-to-Speech and Speech Corpus Scraping Are All You Need". This paper emphasizes the importance of speech command recognition in the field of artificial intelligence. For generating synthetic speech commands, we used a neural text-to-speech system called Piper, which offers five voices for the Kazakh language. The models for other languages are also available. To extract speech commands from a large-scale speech corpus, we utilized the Vosk Speech Recognition Toolkit. To increase the size of the dataset, we applied a data augmentation method to both the synthetic dataset and the speech corpus scraped dataset. More details about these augmentation techniques can be found in this github repository.
The primary objective of our research paper was to examine the feasibility of deploying our model on a single board computer, such as the Raspberry Pi, utilizing frameworks like Tensorflow Lite and the ONNX runtime. While this initial investigation proved promising, our current hackster project seeks to shift our focus towards deploying the model on even small devices, a field known as TinyML. Popular solutions using central processing unit (CPU), graphics processing unit (GPU), or tensor processing unit (TPU) architecture has shown high flexibility and speed in Machine learning model inference, but it is no longer feasible in TinyML for the much stricter constraints on hardware resources and power consumption. TinyML aims to implement machine learning applications on small, and low-powered devices like microcontrollers(MCU).
In this project on Hackster, our aim is to create a Keyword Spotting Application (KWS) capable of classifying 28 different output classes. The application will be able to recognize a custom set of keywords in Kazakh Language using the Arduino Nicla Voice development board.
Overview of Arudino Nicla Voice development board
The Arudino Nicla Voice stands out as one of the most advanced TinyML development boards available in the market. The Arduino Nicla Voice development board incorporates cutting-edge features including a high-performance microphone, an IMU (Inertial Measurement Unit), a Cortex-M4 Nordic nRF52832 MCU (Microcontroller Unit), and the Syntiant NDP120 Neural Decision Processor.

The Arduino Nicla Voice
The NDP120 is equipped with an Arm Cortex M0 processor with 48kbyte SRAM, dual-timers and UART functionality and a HiFi-3 DSP. The NDP120’s embedded Syntiant Core 2 supports more than 7 million parameters and can process multiple concurrent heterogeneous networks. It can run multiple applications simultaneously at under 1mW. So basically, Arduino Nicla Voice has an ARM Cortex M0 (Von Neumann Architecture) and an ARM Cortex M4 (Harvard Architecture) and both processors can access shared memory.
As mentioned above, TinyML tries to implement machine learning applications on microcontrollers. Therefore, the challenge is how to adapt machine learning algorithms to be used by low-powered devices. Most microcontrollers have less than 500KB of read-only storage in flash, and many have only tens of kilobytes. For example, the Arduino Nano 33 BLE Sense has 1 MB CPU flash memory and 256 KB SRAM. The good news is that the NDP120 device is equipped with only 640 kilobytes of onboard memory dedicated to storing neural network parameters. NDP120 is specially designed for accelerating the inference on the tinyML devices for speech application. To optimize the model and make it compatible with the limited memory, we must employ quantization techniques and convert it to the TensorFlow Lite Micro format with int8 precision. TensorFlow Lite Micro is a machine learning framework for microcontrollers. It provides low memory usage and power consumption. Fortunately, we have the advantage of utilizing Edge Impulse, a SaaS web tool that can assist us in training and deployment.
Training using Edge Impulse platform
Edge Impulse offers an end-to-end solution for deploying models on TinyML devices. The process begins with data collection using IoT devices, followed by feature extraction, model training, and finally, deployment and optimization for TinyML devices.
In total, we have gathered 20 hour and 15 minutes worth of data that can be categorized into 28 distinct classes in Kazakh language.
Command (Kazakh) -"артқа", "алға", "оңға", "солға", "төмен", "жоғары", "жүр", "тоқта", "қос", "өшір", "иә", "жоқ", "үйрен", "жаз", "орында", "нөл", "бір", "екі", "үш", "төрт", "бес", "алты", "жеті", "сегіз", "тоғыз", "оқы", "белгісіз", "шу".
Command (English) - "backward", "forward", "right", "left", "down", "up", "go", "stop", "on", "off", "yes", "no", "learn" ", "write", "follow", "zero", "one", "two", "three", "four", "five", "six", "seven", "eight", "nine", "read", "unknown", "noise"By utilizing the Fourier transform, we have the ability to break down the audio signal and acquire the frequency domain and time representation of each keyword.We observed that the model accuracy of a neural network using Dense Neural network on Arudino Nicla Voice is significantly higher than 2D Convolutional network.
The model has the following structure:

Diagram of Dense Neural network
For this project, the number of training cycles was set to 100 and the learning rate was set to 0.0005.
After training is complete, Edge Impulse Studio will display the performance of the model, a confusion matrix, feature explorer, and on-device performance details.
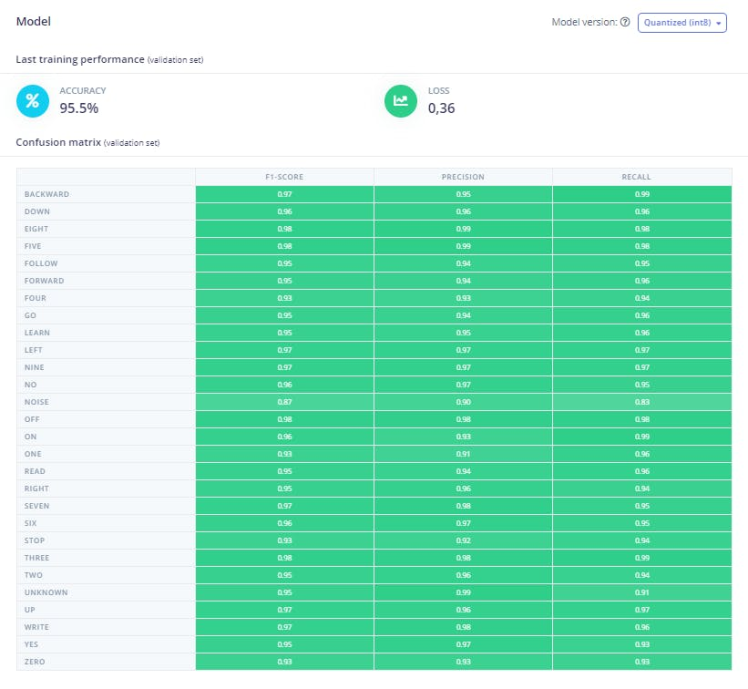
As you can see, the model trained has 28 output classes. The accuracy obtained is 95.5% and a loss of 0.36. This result could be optimized by fine-tunning the training hyperparameters.
You might see below log messages:
Total params: 548,636
Total Parameter Memory: 538.25 KB out of 640.0 KB on the NDP120_B0 device.Above information is important because it indicates the memory efficiency of the model and whether it can be deployed on resource-limited devices like Arduino Nicla Voice. Hopefully, the quantization process can increase the performance of the inference, as going from a 32-bit floating point to a 8-bit integer representation can reduce the size of the model, but it means a loss in precision. A total of 548, 636 parameters were required to our KWS application, which is 538.25 KB out of 640.0 KB of onboard memory for neural-network parameters.
It is always interesting to take a look at a model architecture as well as its input and output formats and shapes. You can use a program like Netron to view the neural network.
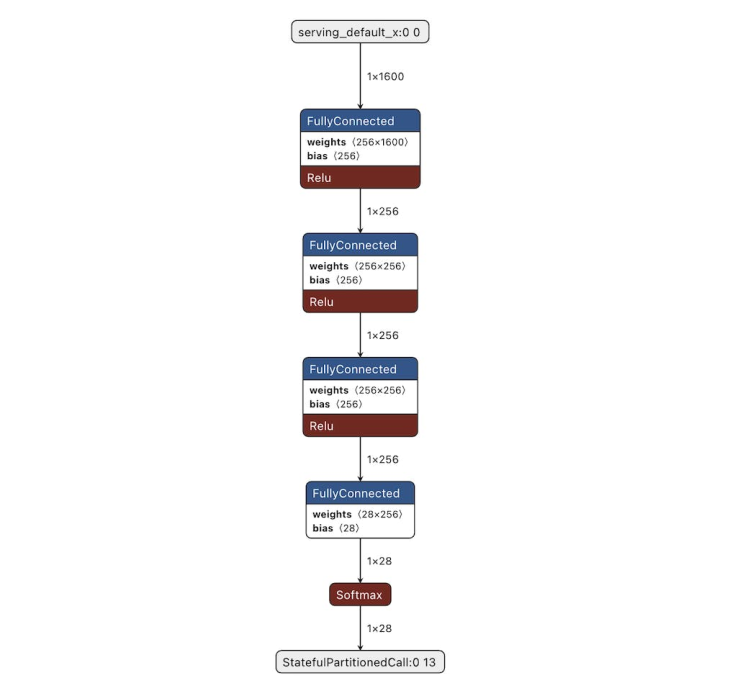
Finally, we can deploy the model to use it in a KWS application.
Deployment and Inference
Now, we can deploy the trained model into the Arduino Nicla Voice to run the keyword spotting application. Click the the Deployment menu item in Edge Impulse Studio, and then press the Arduino Nicla Voice button.
Here is a demonstration video of what the final result looks like. Although you may not understand the Kazakh language in this demonstration video, I can assure you that the Arduino Nicla Voice, which is equipped with NDP120 showcases impressive inference speed and near-perfect accuracy.
Demo videoThis tiny device has the capability to accurately classify 28 different classes for the Keyword spotting task in Kazakh language. We can conclude that by leveraging advanced machine learning techniques, we generate compact and powerful models that can detect specific keywords or phrases with minimal computational resources on the small edge devices like Arduino Nicla Voice.
This project was made possible through the support, guidance, and assistance of the staff of Institute of Smart Systems and Artificial Intelligence. I hope you found this research study useful and thanks for reading it. If you have any questions or feedback, leave a comment below. If you find our project valuable, go to our repository on GitHub and give it a star. Thanks!
References
- Speech Command Recognition: Text-to-Speech and Speech Corpus Scraping Are All You Need
- Syntiant to Introduce Turnkey Edge AI Security Solution at CES 2023
- Official PyTorch implementation of "Attention-Free Keyword Spotting", Mashrur. M. Morshed & Ahmad Omar Ahsan, PML4DC @ ICLR 2022.
- Machine Learning for Microcontroller-Class Hardware - A Review
- Tiny Machine Learning for Concept Drift
- TinyML: From Basic to Advanced Applications
- Watch Syntiant’s 1-Milliwatt Chip Play Doom
Code
Credits
Related products
















Leave your feedback...