

Ai Stethoscope With Viam

Made by CodersCafeTech / Artificial intelligence / Fitness / Health / Robotics / Sensors
About the project
Your personal doctor at your fingertips!
Project info
Difficulty: Moderate
Platforms: Android, Autodesk, Google, Microsoft, Raspberry Pi
Estimated time: 6 days
License: Apache License 2.0 (Apache-2.0)
Items used in this project
Hardware components

View all
Story
In an era marked by rapid advancements in technology and a growing emphasis on personal health and wellness, the emergence of innovative medical devices has become increasingly prevalent. Among these innovations stands the AI Stethoscope, a device designed to revolutionize home healthcare by providing users with convenient and reliable access to medical diagnostics.

The AI Stethoscope represents a significant step forward in the democratization of healthcare. Unlike traditional stethoscopes, which rely solely on the expertise of trained professionals for interpretation, this device leverages cutting-edge machine-learning algorithms to analyze a wide range of bodily sounds and provide real-time health assessments.
At its core, the AI Stethoscope offers users the ability to monitor various aspects of their health from the comfort of their own homes. From detecting heart diseases with AI to streaming your heart sounds to a doctor and beyond, the device empowers individuals to take a proactive approach to their well-being, enabling early detection of potential health issues and facilitating timely intervention.
However, the potential of the AI Stethoscope extends far beyond its current capabilities. As advancements in artificial intelligence continue to evolve, so too will the functionalities of this innovative device. Future iterations will include expanded diagnostic capabilities, personalized health recommendations, and seamless integration with other home healthcare devices, further enhancing its utility and impact.
Video
Classic Stethoscope
First things first. Let's start by dissecting the stethoscope. The stethoscope has long been a staple tool in the medical field, serving as a vital instrument for auscultation, a technique used to listen to internal body sounds, primarily those of the heart and lungs. With its simple yet effective design, the stethoscope enables healthcare professionals to detect a wide range of physiological sounds, from normal heartbeats and breathing patterns to subtle murmurs and irregularities.

The design typically consists of a chest piece (called the diaphragm or bell) connected to earpieces via flexible tubing. When placed on the body, the stethoscope transmits sounds from the internal organs to the listener's ears, allowing for the detection of various physiological sounds.
By amplifying and transmitting these sounds to the listener's ears, the stethoscope provides valuable insights into the functioning of vital organs, facilitating the diagnosis and monitoring of various medical conditions. Despite its humble origins, the stethoscope remains an indispensable tool in modern medicine, embodying the fundamental principles of patient care and diagnostic excellence.
Giving Intelligence to Stethoscopes with Machine Learning
Machine learning models can be instrumental in detecting heart diseases by analyzing heart sounds, a process known as auscultation. Through advanced algorithms, these models can discern subtle patterns and anomalies within the heart's acoustic signals, offering valuable insights into the presence of cardiac abnormalities.
Firstly, data collection is crucial, where recordings of heart sounds from a diverse range of patients with and without heart diseases are amassed. These recordings serve as the training data for the machine learning model, providing the necessary information for pattern recognition.
Once trained, the model can analyze new heart sound recordings with remarkable accuracy. It identifies characteristic features associated with various heart conditions, such as murmurs, irregular rhythms, or valve abnormalities. By comparing these features to patterns observed in the training data, the model can confidently classify the presence or absence of specific heart diseases.
Furthermore, continual refinement of the model is essential for improving its accuracy and robustness. This involves feeding it with additional data and fine-tuning its parameters to enhance its performance over time.
So we have our mind map to train the machine learning model to detect heart diseases using heart sounds. Let's begin by collecting some medical data.
1. Data Collection
It is incredibly difficult to accumulate a very good dataset with diverse heart conditions. So we are opting for a public dataset that has data for almost 4 different common heart diseases including Aortic Stenosis(AS), Mitral Regurgitation(MR), Mitral Stenosis (MS), Mitral Valve Prolapse(MVP), and Normal Heart conditions.
The dataset is subdivided into 5 classes with each class having 200 recorded audio.wav files with a duration of 4 to 5 seconds.
2. Data Preprocessing
With the limited amount of data, it is always better to train a transfer-learning model. So we are using Yamnet as our base model and we're building our model on top of Yamnet for better performance and easiness of our model training. So it is important to preprocess the data according to the specification of Yamnet.
YAMNet is an audio event classifier that takes audio waveform as input and makes independent predictions for each of 521 audio events from the AudioSet ontology. The model uses the MobileNet v1 architecture and was trained using the AudioSet corpus.
The model accepts a 1-D float32 Tensor or NumPy array containing a waveform of arbitrary length, represented as mono 16 kHz samples in the range [-1.0, +1.0]. Internally, it frames the waveform into sliding windows of length 0.96 seconds and hop 0.48 seconds, and then runs the core of the model on a batch of these frames.
The sampling rate of our dataset is 8kHz and it is mono audio. So before feeding it to the model we will have to resample and preprocess the audio files accordingly.
Also, it is important to split the model into training and testing sets. The train-to-test ratio is kept at 80:20. Further the training data is subdivided into training and validation data in the same ratio of 80:20. So out of 200 audio samples for a class we have 128 train samples, 32 validation samples, and 40 test samples.
3. Transfer Learning Model
Transfer learning is a machine learning technique where a model trained on one task is re-purposed or adapted for a different, but related, task. Instead of starting the learning process from scratch, transfer learning allows us to leverage knowledge gained from solving one problem to solve a different problem.
By transferring learned features or representations from the source task to the target task, transfer learning can significantly reduce the amount of labeled data required for training and improve the performance of the model on the target task. This approach is particularly useful when labeled data is scarce or expensive to obtain for the target task, as it enables the model to generalize better and learn more effectively with limited data.
Yamnet
YAMNet is a deep learning model developed by Google for sound event detection. While YAMNet is primarily trained on a large-scale dataset for general sound classification tasks, it can potentially be leveraged for detecting heart diseases using stethoscope sounds through transfer learning.
Transfer learning involves taking a pre-trained model, such as YAMNet, and fine-tuning it on a specific task, in this case, detecting heart diseases from stethoscope sounds. Here's how YAMNet transfer learning could be beneficial for us:
- Feature Extraction: YAMNet has already learned to extract useful features from sound data through its training on a diverse dataset. These features capture various aspects of sound, including pitch, frequency, and timbre, which could be relevant for distinguishing different heart sounds associated with various cardiac conditions.
- Reduced Data Requirements: Training a deep learning model from scratch for heart disease detection would require a large labeled dataset of stethoscope recordings, which can be time-consuming and expensive to collect. By leveraging YAMNet as a starting point, transfer learning allows us to train a model with a smaller dataset, as YAMNet has already learned generic sound features that are likely relevant to heart sounds.
- Faster Convergence: Transfer learning often leads to faster convergence during training since the model starts with pre-trained weights that are already optimized for a similar task. This means that with transfer learning, we can achieve good performance on heart disease detection with fewer training epochs.
- Generalization: YAMNet has been trained on a diverse range of sound events, which helps it generalize well to different types of sound data, including stethoscope recordings of heart sounds. This generalization capability is essential for detecting heart diseases accurately across different patients and conditions.
4. Model Training
We've done an extensive model training process on Google Colab, with TensorFlow serving as our primary framework. The intricate steps and particulars necessary for model training are meticulously outlined and elaborated upon within this Jupyter Notebook.
5. Model Testing
Model testing is a crucial phase in the development lifecycle where the trained model's performance is evaluated on unseen data to assess its generalization capability and effectiveness. This evaluation helps determine how well the model can perform on new, previously unseen examples, indicating its reliability and potential for real-world deployment.
In our case, after training our ML model, we subjected it to testing to evaluate its performance. Our results indicate that our model achieved a training accuracy of 94% and a testing accuracy of 93%. This signifies that our model performs consistently well not only on the training data but also on new, unseen data, demonstrating its ability to generalize effectively and make accurate predictions in real-world scenarios.
6. Deployment
To deploy a TensorFlow model using the SavedModel format, first, save the trained model using tf.saved_model.save(). Once saved, load the model using tf.saved_model.load(). Next, choose the deployment option that suits your needs, such as TensorFlow Serving for server deployment, TensorFlow Lite for mobile devices, or TensorFlow.js for web applications. We opted for a TensorFlow Saved Model format and you'll see why we opted for that format in the coming steps.
Building Smart Machines With VIAM
Viam is an open-source software platform designed to simplify working with smart machines. It streamlines the process of building, monitoring, and managing data from a wide range of devices. From industrial robots with complex movements to tiny sensors collecting real-time data, Viam can handle it all.
By offering flexible cloud solutions, Viam bridges the gap between software and the physical world of hardware. This empowers engineers to effectively manage a multitude of sensors, machines, and devices, all at scale. Viam even incorporates artificial intelligence (AI) capabilities, allowing developers to easily add intelligence to any device. With Viam, making any machine smarter becomes a quicker and more manageable task.
Getting Started With Viam
After you sign up to Viam, you will be redirected to your Viam home page, as shown below.
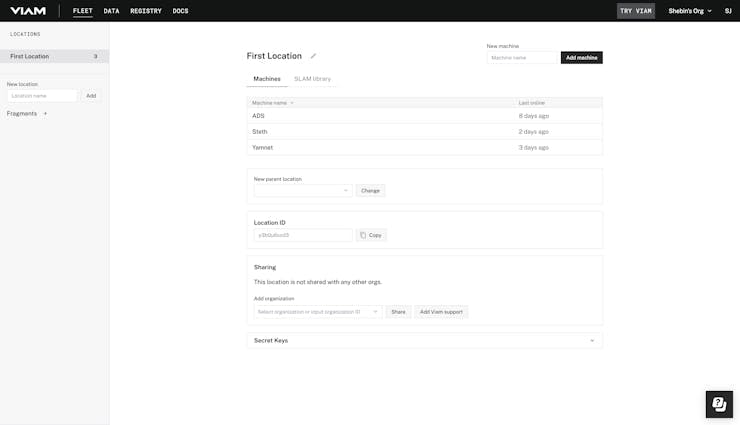
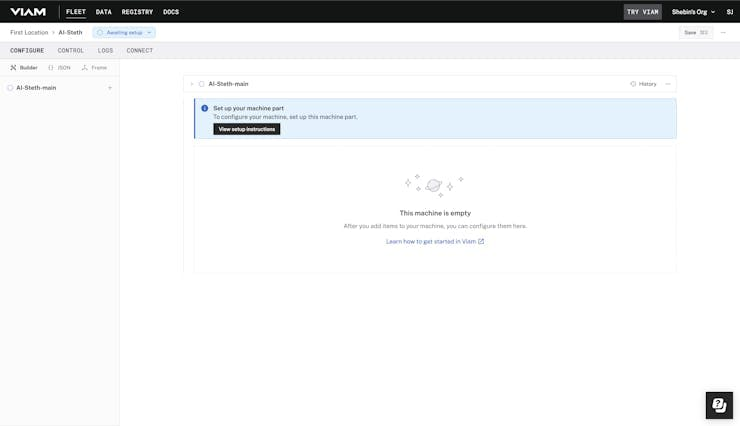
You can simply start by creating a smart machine using Add Machine. Give it a name and there it is. It is your smart machine and you'll be redirected to the builder page as shown here.
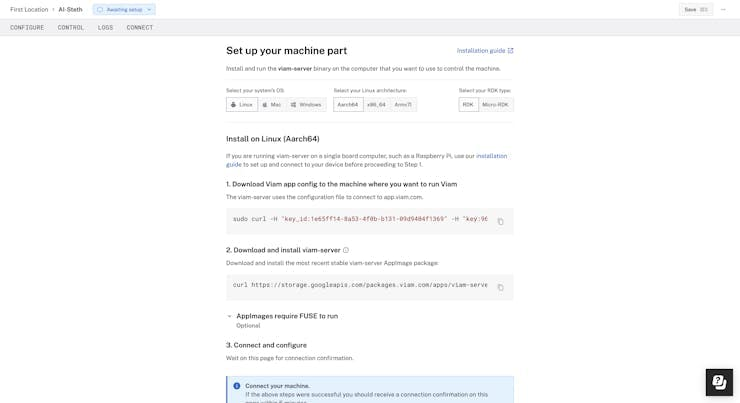
Upon clicking the View setup instructions you'll get two commands that can be used to set up viam-server on your physical device.
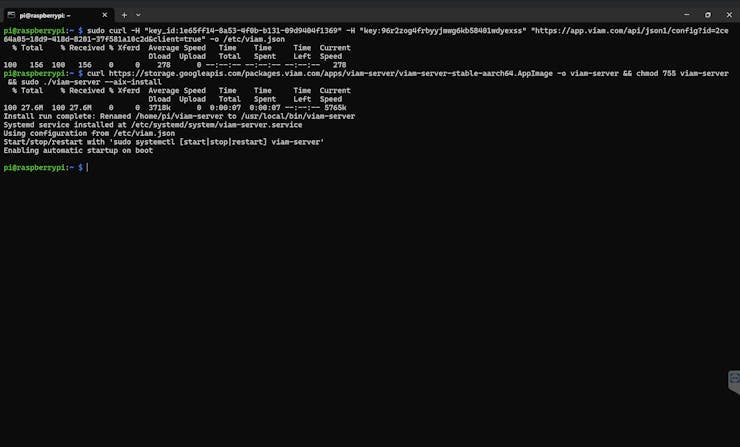
Now the viam-server is installed on your Raspberry Pi and is configured to autostart on reboot. Or you can start it using this command.
sudo systemctl start viam-serverAfter starting viam-server wait till your machine comes online.
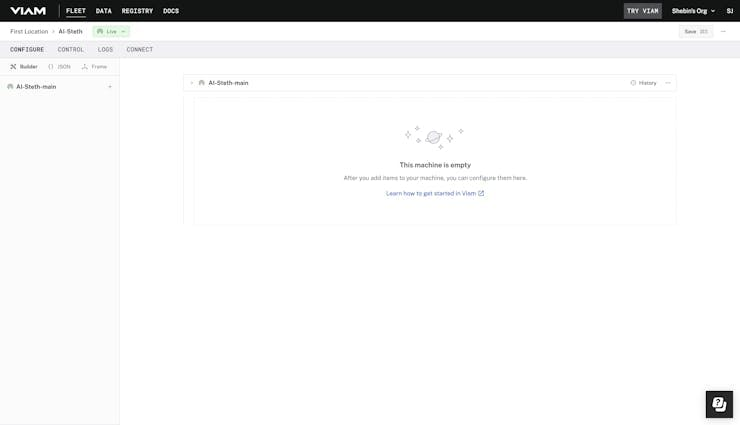
Now let's start by adding some components. We can add a board component which in our case is pi (Raspberry Pi), but we're kind of ignoring that as we don't have to directly interact with the board or the gpio pins. Instead, we can start adding services. We are using mainly 2 services - The tensorflow-cpu service as well as the pubsub:service:mqtt-grpc from viam-labs. Let's start by adding and configuring them one by one.
The tensorflow-cpu service:
The tensorflow-cpu module of the Viam mlmodel service allows CPU-based inference on a Tensorflow model.
This service requires only one compulsory attribute, but we generally give 2, whereas the second one is optional.
{
"model_path": "/home/pi/AI-Steth/",
"label_path": "/home/pi/AI-Steth/labels.txt"
}model_path: Path to folder containing TensorFlow saved model
label_path: Path of label file

The pubsub:service:mqtt-grpc
This module implements the viam-labs pubsub API in a viam-labs:service:mqtt-grpc model. With this service, you can interact with MQTT brokers to publish and subscribe to topics in our projects.
This service requires two compulsory attributes, but we have given 3 as we are using websockets instead of default TCP.
{
"mqtt_transport": "websockets",
"port": 8080,
"broker": "test.mosquitto.org"
}broker: IP or hostname of MQTT broker
port: Port for connection(default 1883)
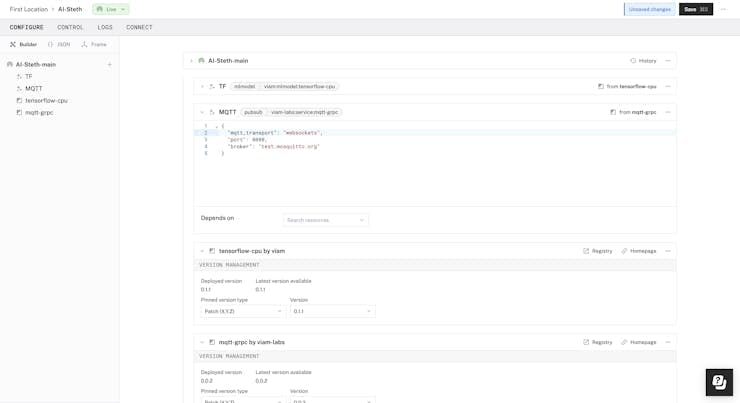
After saving the config we need to wait for a few minutes while viam-server installs and starts up the modules. It is quite interesting to watch the logs update as the viam-server sets up everything one by one.
After a few minutes of waiting, everything is online and ready to dash.
Testing the Setup
To ensure that the services have been properly installed we have two test codes that will ensure both of the services are working fine.
Let's test the TensorFlow service with some test data from the Model Training test set. We are using a sample under the category 'AS' and see whether the model can detect it or not.
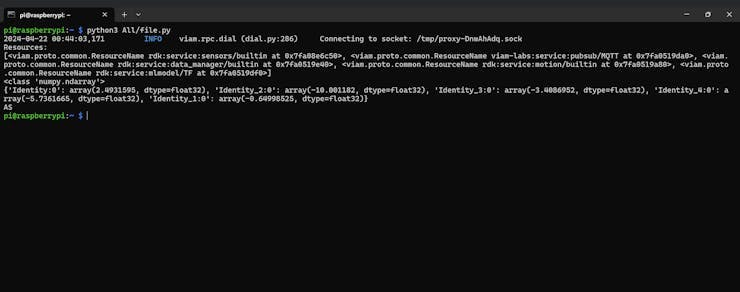
Yeah, it works!
Now it's time to collect some hardware and build a setup to do inferencing using real-world heartbeat sounds.
Hardware Setup
The basic hardware setup consists of mainly 3 parts,
1. A microphone with 3.5mm output which can be used to interface the Stethoscope with the Raspberry Pi
2. A sound card
3. Raspberry Pi 4/5
1.BoyaBY-M1 Omnidirectional Microphone
The Boya BY-M1 microphone is an omnidirectional polar pattern mic, ensuring it captures sound from all directions with equal sensitivity. Its flat frequency response ensures faithful reproduction of audio across the entire frequency spectrum, delivering clear and accurate sound quality.

With its high-quality construction and components, the BY-M1 microphone excels in capturing detailed and natural audio, making it an excellent choice for our usage.
2. Sound Card
Raspberry Pi doesn't come with a built-in audio input. So a sound card is necessary for such purposes. A sound card is a hardware component that facilitates audio input and output on a computer.

It typically features a USB interface on one end for connecting to the computer and 3.5mm jacks for microphone and speaker connections on the other end. Sound cards enable users to listen to audio through speakers or headphones and capture audio through microphones, enhancing the overall multimedia experience on the computer.
3. Raspberry Pi 5
The Raspberry Pi 5 is a versatile single-board computer (SBC) renowned for its compact size, affordability, and impressive performance capabilities. Featuring a quad-core ARM Cortex-A78 processor running at up to 2.0GHz, along with options for 4GB, 8GB, or 16GB of RAM, the Raspberry Pi 5 offers significant computational power suitable for a variety of tasks.

The Raspberry Pi 5 also includes multiple USB ports, Gigabit Ethernet, dual-band Wi-Fi, Bluetooth 5.2, and micro HDMI ports for connecting to displays. With its GPIO pins, camera interface, and support for various operating systems such as Raspberry Pi OS, Ubuntu, and others, the Raspberry Pi 5 serves as an ideal platform for learning programming, building projects, and even serving as a low-cost desktop computer or media center. Its versatility, affordability, and strong community support have made it immensely popular among hobbyists, educators, and professionals alike.
Hardware Testing
Below are the hardware connections that have been made to test the setup ensuring sound is properly propagated and reaches the machine learning network undistorted.

Now let's test the setup by playing the test audio again. And it works well!
Building AI Stethoscope
Now we have successfully completed our setup. So to make the AI stethoscope a handheld and portable device we thought of using a smaller board that is comparable to RPI 4 in performance. So we opted for Raspberry Pi Zero 2W.
Now it is quite simple just unplug the SD card RPI 4 and plug it in RPI Zero 2W. But there's a catch! After porting everything from Raspberry Pi 4 to Raspberry Pi Zero 2W, we expect everything to work. Ideally, it should work, but it didn't. And there arises another problem. Just compiled a question on the Viam Discord community and after a few minutes, we have our solution.

Now we have to convert the TensorFlow model into a TensorFlow Lite model. Just wrote a few lines of code that will convert the TF model to a TFLite model.
import tensorflow as tf
converter = tf.lite.TFLiteConverter.from_saved_model(model_path)
tflite_model = converter.convert()
with open("converted_model.tflite", "wb") as f:
f.write(tflite_model)Now go back to the Viam builder tab and change the tensorflow-cpu service to the TFLite-CPU service and in the attributes provide the TFLite model path.
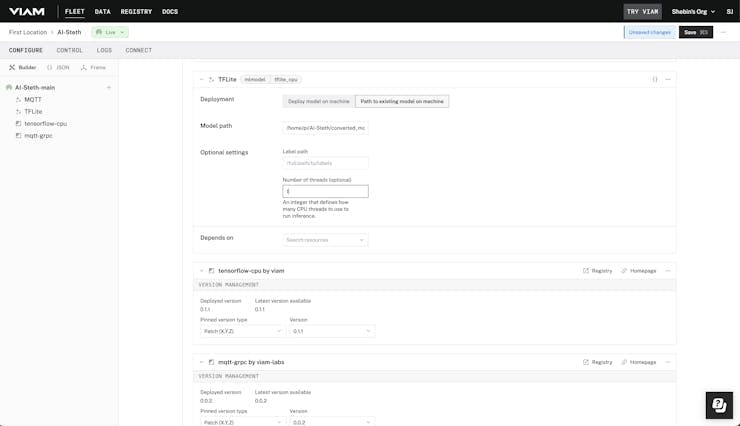
Now test the audio again to make sure everything is working fine. Now it's time to add some additional hardware to make the device independent and portable.
Raspberry Pi Zero 2W

The Raspberry Pi Zero 2 W is a compact and affordable single-board computer that offers impressive performance in a tiny package. With a quad-core ARM Cortex-A53 processor running at 1GHz, 512MB of RAM, and built-in wireless connectivity (Wi-Fi and Bluetooth), the Raspberry Pi Zero 2 W provides a versatile platform for various projects and applications. It features a microSD card slot for storage, a micro HDMI port for connecting to displays, and a micro USB port for power and connectivity.
Despite its small size, the Raspberry Pi Zero 2 W is capable of running a wide range of software, including operating systems like Raspberry Pi OS, making it suitable for IoT projects, embedded systems, and DIY electronics projects where space and budget are limited. Its affordability and versatility make it a popular choice among hobbyists, students, and makers looking to explore the world of computing and electronics.
LiPo Battery
For the AI stethoscope, a 100mAh LiPo battery is used to power the device. This battery has a nominal voltage of 3.7 volts and can output a maximum voltage of 4.2 volts when fully charged.

The compact size and high energy density of the LiPo battery make it an ideal choice for portable electronic devices like the AI stethoscope, providing the necessary power while minimizing weight and size constraints.
DC-DC Charge Discharge Integrated Module
When dealing with a situation where a Raspberry Pi operates at 5V, but LiPo batteries can only provide up to 4.2V when fully charged, a voltage boost converter module becomes essential. This module serves to bridge the voltage gap and ensure stable power delivery to the Raspberry Pi.

This module, designed with a normally open 5V output, ensures uninterrupted power flow, remaining unaffected by load access and enabling simultaneous charging and discharging. Equipped with a robust power management circuit, it seamlessly boosts power from lithium batteries while incorporating battery protection for enhanced safety.
User-friendly features include button-controlled output and a 4-level charge/discharge electricity indicator, offering straightforward control and monitoring. Built for efficiency, this module achieves a charge efficiency of up to 91% and a discharge efficiency of up to 96%, striking an optimal balance between input and output to extend its service life.
But this module does not have any standard charging input, so to mitigate that issue we have used this tiny micro USB break-out module.

Case
We have used Fusion 360 to design an enclosure for this project.
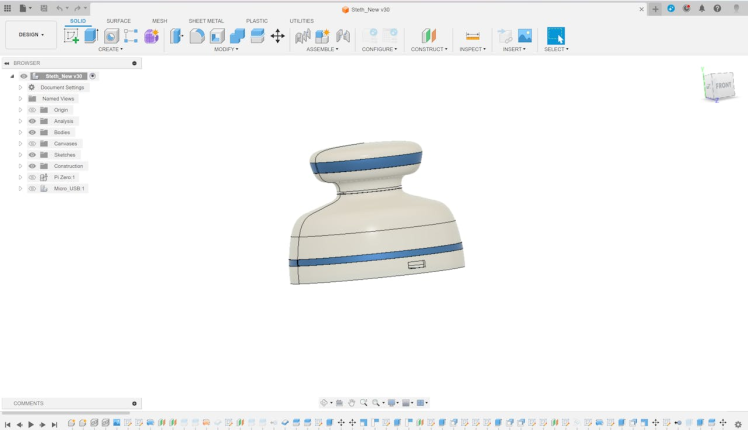
The parts are then 3D printed using PLA filament and will look like this before cohering them together.

Assembly
To save space in this device we have removed the cases of the USB sound card and will make direct connections between the RPi and this sound card module.

Then we started assembling the device.



Companion App
We have designed a companion app for the AI stethoscope. The companion app uses MQTT to communicate between the device and the app. Currently, we have 2 modes - Analysis mode in which the heartbeat is analyzed by AI to find any potential diseases, and Stream mode in which the heartbeat sound is streamed to the doctor using the dashboard.
The dashboard is designed using HTML, CSS, and JS and uses the MQTT JS library to give MQTT capabilities to the dashboard.
Final Product

Future Developments
- Enhanced AI Algorithms: Continuously improving and fine-tuning the AI algorithms to enhance the accuracy and efficiency of heart disease detection.
- Integration with Cloud Services: Integrating the AI stethoscope with cloud services for data storage, analysis, and remote monitoring, allowing for real-time insights and collaboration with healthcare professionals.
- Expanded Sensor Capabilities: Incorporating additional sensors, such as temperature and blood oxygen level sensors, to provide more comprehensive health monitoring capabilities
- Wireless Connectivity: Implementing wireless connectivity options, such as Bluetooth or Wi-Fi, for seamless data transfer and remote access to health data.
- User Interface Enhancements: Develop user-friendly interfaces, including mobile apps or web portals, to provide intuitive controls and visualizations for users and healthcare providers.
- Customization and Personalization: Offering customization options to tailor the AI stethoscope to individual user preferences and healthcare needs.
- Cost Reduction and Scalability: Exploring cost-effective manufacturing processes and materials to reduce production costs and increase scalability for mass adoption
Schematics, diagrams and documents
CAD, enclosures and custom parts
Code
Credits
Related products
















Leave your feedback...