

Teachable Machine

Made by knaveen / Artificial intelligence / Voice
About the project
A voice-enabled machine which reads book and replies to the questions.
Project info
Difficulty: Difficult
Platforms: Intel, Raspberry Pi, Seeed Studio
Estimated time: 1 day
License: Apache License 2.0 (Apache-2.0)
Items used in this project
Hardware components

Software apps and online services
Story
Introduction
In this project I built a voice-enabled teachable machine which can scan text from a book pages or any text source and convert that to a context and users can ask questions related to that context and the machine can answer just using the context. I always wanted to make such kind of edge device which is easy to deploy and can be trained for a given context effortlessly without needing any internet connection.
Machine Learning Models used in the Application
Three machine learning models are used:
1. Tesseract OCR (LSTM based model)
Tesseract is an OCR engine with support for unicode and the ability to recognize more than 100 languages out of the box. It can be trained to recognize other languages.
2. DeepSpeech (TensorFlow Lite model)
DeepSpeech is an open source Speech-To-Text engine, using a model trained by machine learning techniques which Google's TensorFlow to make the implementation easier.
3. BERT
BERT is a language representation model which stands for Bidirectional Encoder Representations from Transformers. The pre-trained BERT model can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial task-specific architecture modifications.
The first 2 models run at Raspberry Pi 4 and the last one runs at the Intel Neural Compute Stick 2 using the OpenVINO Toolkit.
Installation Instructions
Please follow the step by step instructions given below to download and install all prerequisites for the application. It is assumed that the Raspberry PI OS (formerly Raspbian) is already installed and SSH, Audio, SPI, I2C, and Camera are enabled using raspi-config utility.
Install the OpenVINO Toolkit for Raspberry Pi OS
- $ sudo apt update$ sudo apt install festival cmake wget python3-pip
- $ mkdir -p ~/Downloads
- $ cd ~/Downloads
- $ wget https://download.01.org/opencv/2020/openvinotoolkit/2020.4/l_openvino_toolkit_runtime_raspbian_p_2020.4.287.tgz
- $ sudo mkdir -p /opt/intel/openvino
- $ sudo tar -xf l_openvino_toolkit_runtime_raspbian_p_2020.4.287.tgz --strip 1 -C /opt/intel/openvino
Set USB Rules
- $ sudo usermod -a -G users "$(whoami)"
Now logout and re login.
Initialize the OpenVINO Environment
- $ source /opt/intel/openvino/bin/setupvars.sh
Install the USB rules for the Intel Neural Compute Stick 2
- $ sh /opt/intel/openvino/install_dependencies/install_NCS_udev_rules.sh
Now plug in the Intel Neural Compute Stick 2.
Festival (speech synthesis systems framework) Configuration
Replace the following line in the /etc/festival.scm:
(Parameter.set 'Audio_Command "aplay -q -c 1 -t raw -f s16 -r $SR $FILE")
with the line below:
(Parameter.set 'Audio_Command "aplay -Dhw:0 -q -c 1 -t raw -f s16 -r $SR $FILE")
Install driver for Respeaker 2-mics PI HAT
- $ cd ~
- $ git clone https://github.com/HinTak/seeed-voicecard
- $ cd seeed-voicecard
- $ sudo ./install.sh
- $ sudo reboot
Download the application repository
- $ cd ~
- $ git clone https://github.com/metanav/TeachableMachine
Download the BERT model OpenVINO Intermediate Representation files
- $ cd ~/TeachableMachine
- $ mkdir models
- $ cd models
- $ wget https://download.01.org/opencv/2020/openvinotoolkit/2020.4/open_model_zoo/models_bin/3/bert-small-uncased-whole-word-masking-squad-0001/FP16/bert-small-uncased-whole-word-masking-squad-0001.bin
- $ wget https://download.01.org/opencv/2020/openvinotoolkit/2020.4/open_model_zoo/models_bin/3/bert-small-uncased-whole-word-masking-squad-0001/FP16/bert-small-uncased-whole-word-masking-squad-0001.xml
Download the DeepSpeech model files
- $ cd ~/TeachableMachine/models
- $ wget https://github.com/mozilla/DeepSpeech/releases/download/v0.8.2/deepspeech-0.8.2-models.tflite
- $ wget https://github.com/mozilla/DeepSpeech/releases/download/v0.8.2/deepspeech-0.8.2-models.scorer
Run the application
- $ cd ~/TeachableMachine
- $ pip3 install -r requirements.txt
- $ python3 main.py
How does it work?
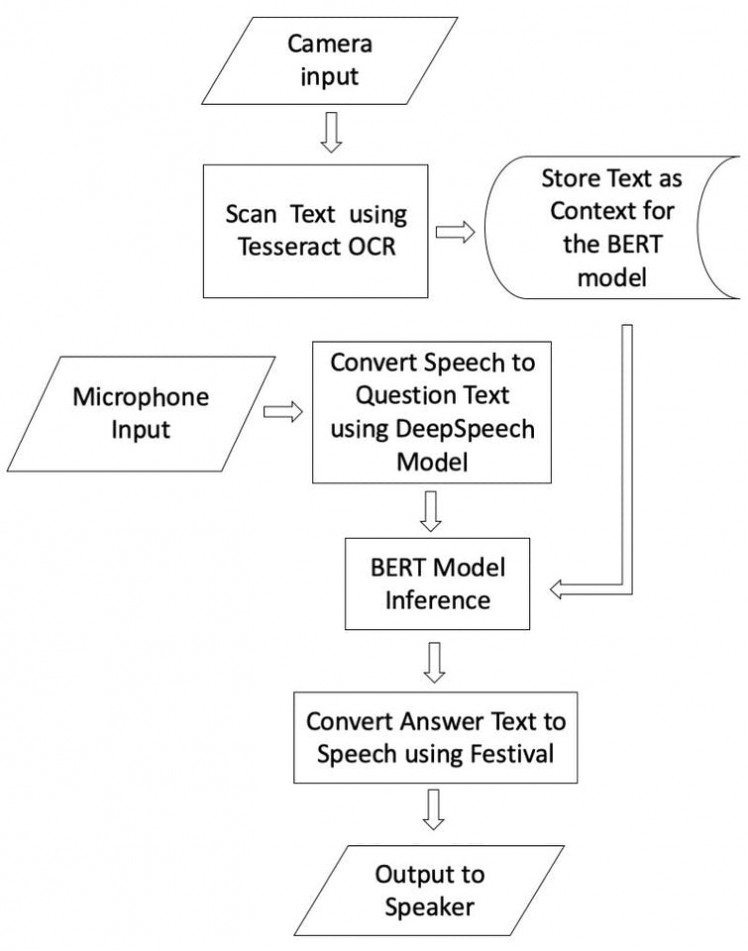
The Raspberry Pi 4 is connected to the ReSpeaker 2-mics PI HAT which is used to receive voice using the onboard microphones. A Raspberry Pi Camera Module is connected to the Raspberry Pi 4 using the CSI2 connector which is used to scan the text in a book. There is a button on the ReSpeaker 2-mics PI HAT which is used to trigger the start of the scanning process. Right after the pressing the button, within 5 seconds user has to show a text (book page or a paper with some meaningful english texts for example, story paragraphs or Wikipedia entries) to the camera. The book page image is captured and converted to the text using the Tesseract OCR application. The captured text is used as a context for the BERT model which is used for answering the questions. The machine requests the user to ask a question. The user asks a question and the question speech is converted to the text using DeepSpeech application. The converted question text is fed into the BERT model running at the Intel Neural Compute Stick 2 and the model infers the answers with the confidence scores. The best answer text is converted to the speech using the Festival application which is played on the Speakers connected to the Raspberry Pi 4 audio output (3.5 mm jack). Please see the schematics section for the connection diagram and see the flowchart below for better understanding of the application flow.
Flowchart
 Demo Video
Demo Video
I would like to thank Intel for providing the Neural Compute Stick 2.
Schematics, diagrams and documents
Code
Credits
Related products












Leave your feedback...