

Efm32 Voice Recognition Project Using Giant Gecko's Leds

Made by SiliconLabs / Lights / Voice
About the project
This project is a program that implements voice recognition for the GG11 using the starter kit’s onboard LEDs.
Project info
Difficulty: Moderate
Platforms: Silicon Labs
Estimated time: 1 day
License: GNU General Public License, version 3 or later (GPL3+)
Items used in this project

Story
Background and motivation:
This project is a program that implements voice recognition for the GG11 using the starter kit’s onboard LEDs. My motivation to work on this project was mainly that I have never done anything remotely close to voice recognition before, and I thought it would be a good challenge. But another motivation was also that I am very interested in the Amazon Echo and the other emerging home assistant technologies.The program works by first learning your voice through a small training protocol where the user says each keyword a couple times when prompted. After the program has learned the user’s voice, the user can turn the LED on, red, blue, green, or off simply by saying “on”, “blue”, “red”, “green”, or “off”.
Description:
My first step was getting audio input from the microphone into the microcontroller and storing it. This proved a little more difficult than I expected because I hadn’t worked with SPI or I2S before. In addition to this, I also had to design a sound detection system that captures as much significant sound as possible. I did this by squaring and summing the elements of the state buffer of the bandpass FIR filter that I apply on each sample and then setting a threshold for the result of that operation. This system turned out to be extremely useful because, in addition to saving processor time, it also time-aligned the data to be processed.
After this step, I began to implement the actual voice recognition. At first, I thought I could just find a library online and implement easily, but this turned out to be far from true. Most voice recognition libraries are much too big for a microcontroller, even one with a very large Flash memory of 2MB like the GG11. There was one library I found that was written for Arduino, but it didn’t work very well. So, I began the process of writing my own voice recognition algorithm.
After a lot of research, I decided I would use Mel’s Frequency Cepstral Coefficients (MFCCs) as the basis for my algorithm. There are a number of other audio feature coefficients, but MFCCs seemed to be the most effective. The calculation of MFCCs is basically several signal processing techniques applied in a specific order, so I used the CMSIS ARM DSP library for those functions.
After beginning work on this, I created a voice training algorithm to allow the program to learn any voice and adapt to any user. The training program has the user say each word a configurable number of times, and then calculates the MFCCs of that person’s pronunciation of the keyword and stores them in flash memory.
Next, because the input data was time-aligned, I could simply put all the MFCCs for the 4 buffers in one array and use that as the basis for comparison. In addition to this, I also calculated and stored the first derivative (delta coefficients) of the MFCC data to increase accuracy.
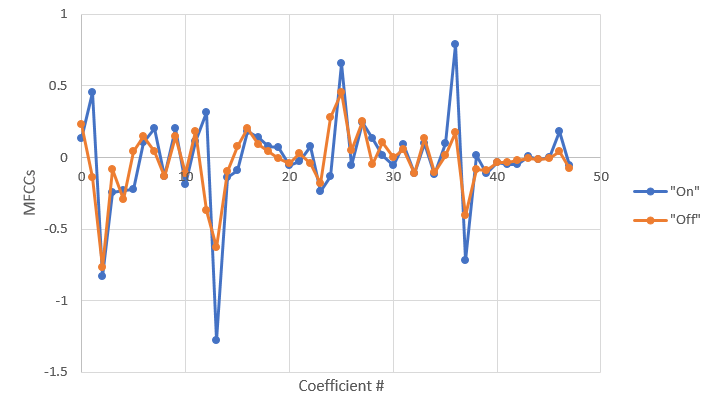
Accomplishments:
- I wrote my own voice recognition algorithm for microcontrollers with relatively little RAM and flash memory usage
- Can store up to 10 keywords in Flash and up to 1,150 keywords in RAM (this number would require program modification to not store in Flash and to use less trainings)
- Successfully created a voice recognition and training technique that works for everyone, no matter their accent or voice, with an excellent success rate
- The program is written in a way that is very easily adaptable for many different uses
- It is well modularized, so if any part of the program is useful to a specific application, it can be easily separated from the rest of the code
Lessons Learned and Next Steps:
- I learned how voice recognition algorithms generally work and how to implement them
- I learned lots of signal processing, as I didn’t know anything about it before
- I learned how to read a large library like emlib more efficiently
- I learned about large program organization and good general coding practice: this was the biggest software project I have written by far
My next steps are to apply the voice recognition to a temperature / humidity controller application, which should be easier than this LED application as the keywords are very different from each other unlike “on” and “off”.
Materials Used:
GG11 STK with microphone and LEDs
Pop filter for STK microphone
Simplicity Studio IDE
CMSIS DSP Library
Download the Source Files (VRLEDs) here:
Credits
SiliconLabs
Silicon Labs provides silicon, software and solutions for a smarter, more connected world.
Related products











Leave your feedback...