
4 Steps To Deploy An Openvino Model To Openncc

Made by Johanna / Artificial intelligence
About the project
Take advantage of Intel OpenVINO Model Zoo's 100+ pre-trained free open-source AI models to make your own AI camera.
Project info
Story
Details
OpenNCC SDK installationPlease install the SDK development environment according to documentation. Such as:
- YOUR OPENNCC SDK INSTALL PATH'/Platform/Linux/readme.md
- We use Linux for a demo, other platforms are also well supported by OpenNCC.
If you still don't have an SDK, you could clone it from github openncc
- To use Model Optimizer and BLOB Converter, please make sure the OpenVINO ToolKit is already installed. You could download the OpenVINO here. And MUST choose the 2020 3 LTS version which was comprehensively tested with OpenNCC.
- If you want to download a model from Open Model Zoo, you need Model Downloader. Or you could also download it from the website.
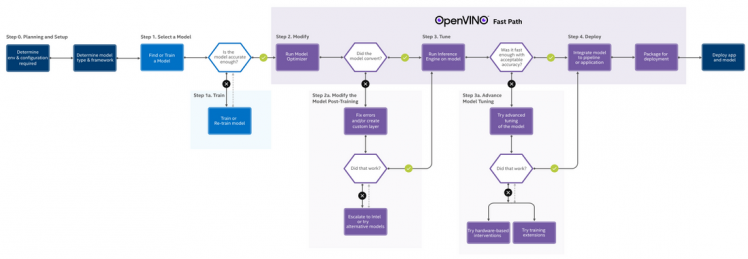
The following figure shows a complete AI model development process:
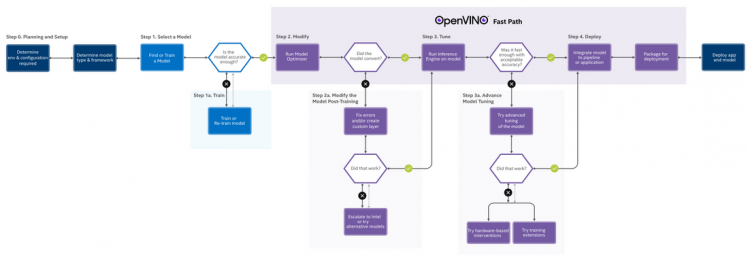
If we start with an existing model, the steps are simplified as follows:
Step1: Prepare a trained model
Use the Open Model Zoo to find open-source, pre-trained, and preoptimized models ready for inference, or use your own deep-learning model.
Download a model from open model zoo,like:
- $./downloader.py --name person-detection-retail-0002
- Note: The OpenNCC supports FP16 format, please use the FP16 model.
Step2: Model Optimizer
Run the trained model through the Model Optimizer to convert the model to an Intermediate Representation (IR), which is represented in a pair of files (.xml and .bin). These files describe the network topology and contain the weights and biased binary data of the model.
- If you download the model from Open model zoo, it is already IR files. So we don't need to run a model optimizer.
- If you use your own model, you need to run a model optimizer, please follow the Model Optimizer Developer Guide.
Step3: Convert to BLOB format
After the model optimization is completed, which means you already have two files(.xml and .bin), the model needs to be converted to the Blob format before it can be deployed on OpenNCC.
You need to run the myriad_compile tool to packet the IR files to a BLOB file, the openncc using the blob file to inference the model.
- Example:
$ ./myriad_compile -m input_xxx-fp16.xml -o output_xxx.blob -VPU_PLATFORM VPU_2480 -VPU_NUMBER_OF_SHAVES 8 -VPU_NUMBER_OF_CMX_SLICES 8
- Note:
The myriad_compile is a tool of OpenVINO ToolKit, you need to install the openvino on your development host. The tool under:
/opt/intel/openvino/deployment_tools/inference_engine/lib/intel64myriad_compile
Step4: Inference on OpenNCC and extract the results
Use the OpenNCC SDK to download the BLOB file, run inference, and output results on OpenNCC Cameras.
The OpenNCC SDK would output two types of streams:
* Normal video stream, support YUV420, YUV422,MJPG, H.264, and H.265
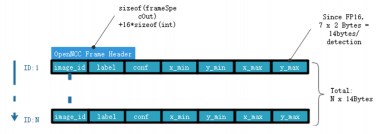
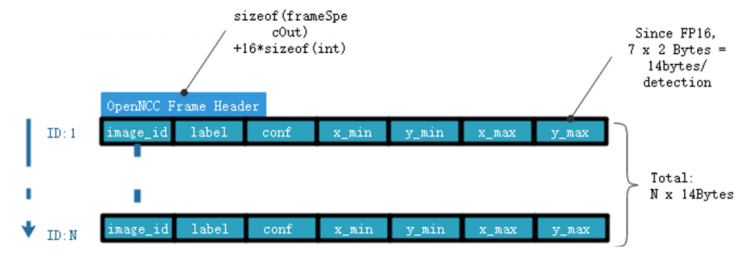
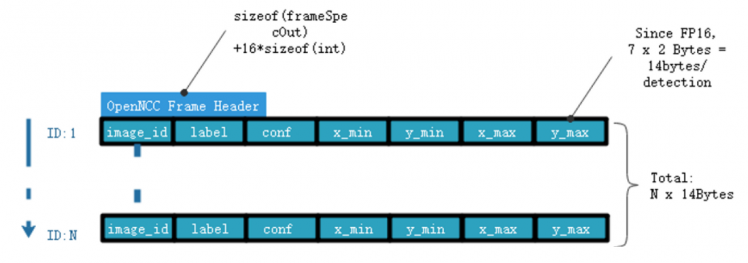
* AI-Meta data stream is the binary results by inference with frame-based data. The specific output structure depends on the model running on OpenNCC.Take the person-detection-retail-0002 model as an example:
- Outputs:
The net outputs "detection_output" blob with shape: [1x1xNx7], where N is the number of detected pedestrians. For each detection, the description has the format: [image_id, label, conf, x_min, y_min, x_max, y_max], where:
image_id - ID of the image in batch
label - ID of predicted class
conf - Confidence for the predicted class
(x_min, y_min) - Coordinates of the top left bounding box corner
(x_max, y_max) - Coordinates of the bottom right bounding box corner.
So the AI-Meta frame you get from SDK would be this:
 Demo and Running
Demo and Running
1. Enter 'YOUR OPENNCC SDK INSTALL PATH'/Platform/Linux/Example/How_to/Load_a_model
2. Copy all the related files from SDK to this demo.
$ ./copy.sh
3. Download the BLOB model file.
In the main.cpp, ........ //5.2 Image preprocessing parameter initialization cam_info.inputDimWidth = 300; cam_info.inputDimHeight = 300; cam_info.inputFormat = IMG_FORMAT_BGR_PLANAR; cam_info.meanValue[0] = 0; cam_info.meanValue[1] = 0; cam_info.meanValue[2] = 0; cam_info.stdValue = 1; // 5.2 Blob file path const char *blob = "./blob/2020.3/object_classification/object_classification.blob"; //6. sdk initialization,and download the model to the openncc ret = sdk_init(NULL, NULL, (char*) blob, &cam_info, sizeof(cam_info)); printf("sdk_init %dn", ret); if (ret < 0) return -1;
We need to load the BLOB model file to the OpenNCC, if your OpenNCC version doesn't have a Flash or EMMC on board.
const char *blob = "./blob/2020.3/object_classification/object_classification.blob";
Here pass the BLOB model file path to the SDK, which you want to run on OpenNCC. You could change the blob file yourself.
4. Get the AI-meta data frame
//Non-blocking read metedata data max_read_size = 512*1024; memset(recv_metedata, 0, max_read_size); if (read_meta_data(recv_metedata, &max_read_size, false) == 0) { memcpy(&hdr, recv_metedata, sizeof(frameSpecOut)); printf("metehdr:type:%2d,seqNo:%-6d,size %d, NCC_T:(%dMS)n", hdr.type, hdr.seqNo,hdr.size, hdr.res[0]); }
5. Post-process to extract the results
5.1 Skip the openncc header
memedata = (char*) recv_metedata + sizeof(frameSpecOut)+16*sizeof(int); obj_show_img_func(yuv420p, cameraCfg.camWidth, cameraCfg.camHeight,scale, src, 1, &cam_info,memedata , min_score);
5.2 Extract the results in obj_demo_show.cpp
.... #define MAX_INTEMS_RESULTS 200 .... uint16_t* cls_ret = (uint16_t*)nnret; //nnret is the point of the ai-meta data .... for (i = 0; i < MAX_INTEMS_RESULTS; i++) { //Since the VPU output FP16 format,we need convert to fp32. int image_id = (int)(f16Tof32(cls_ret[i*7+0])); int label = (int)(f16Tof32(cls_ret[i*7+1])); score =(float)f16Tof32(cls_ret[i*7+2]);
if (image_id < 0) { break; }
x0 = f16Tof32(cls_ret[i*7+3]); y0 = f16Tof32(cls_ret[i*7+4]); x1 = f16Tof32(cls_ret[i*7+5]); y1 = f16Tof32(cls_ret[i*7+6]); }
Credits
Related products












Leave your feedback...