

Raspberry Pi 4 Based Passport Recognition Cam

Made by Johanna / Artificial intelligence
About the project
Application of PaddleOCR.
Project info
Difficulty: Moderate
Platforms: Raspberry Pi
Estimated time: 1 day
License: Apache License 2.0 (Apache-2.0)
Story
Commercial Background
Passport recognition is often used in international traveling scenarios such as customs checking, airports registration, hotel check-in, etc. To improve the effectiveness and efficiency, right now there are many digital passport recognition solutions available in the market, for example, Nanonets, Iris, etc. However, many of them are software solutions and have limitations in hardware customization.
Intel Movidius VPU based OpenNCC edge-AI cameras can freely deploy and run AI models on devices, and its open architecture design allows it to fast-fit to various application scenarios, which makes it easy and convenient to serve as a software & hardware integrated solution.
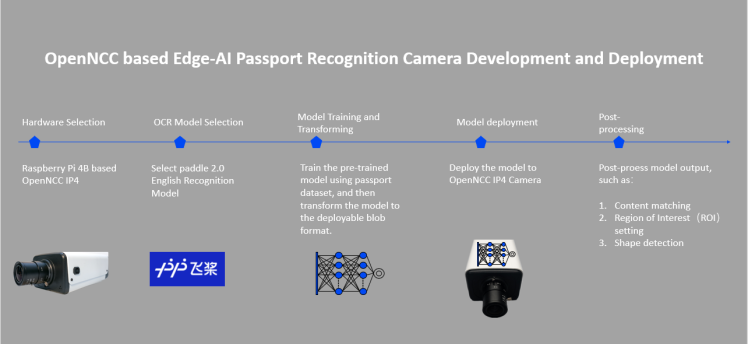
Hardware Selection
For this solution we select Raspberry Pi 4B based OpenNCC IP4, taking advantage of Raspberry Pi’s prosperous ecosystem and rich interfaces. Details about this camera are available on its product page.
Model Selection
Long string recognition is a difficulty in the application of character recognition. In this application we use the English Recognition Model from PaddleOCR, taking advantage of its dynamic graph framework which can make it accurately recognize a long string of characters, in our case, it’s a passport number composed of 46 characters.
Model Training and Transforming
Train the pre-trained model using a specific dataset. Then transform the paddle OCR model to deployable .blob format. We will expand in detail on these processes through subsequent blogs.
Model Deployment
OpenNCC is an edge-AI appliance that supports the replacement of the AI algorithm model on the device side. Therefore, as long as the algorithm model is finally successfully converted into .blob format, it will be very simple to deploy it locally to OpenNCC camera. Detailed deployment instructions will be followed by future blogs.
Data Post-processing
The output of the model without data post-processing is all recognized characters, as shown in the figure below (in order to be more intuitive, all the output recognition results are overwritten to their original location).

Although we have obtained the content, size, and location of each "result block" on the passport, not all character information is useful in real commercial applications. We need to do some data post-processing algorithms according to the application requirements through the host computer program to extract useful information. The following are some post-processing applications that may be used:
1. Characters Matching
In fact, after running the OCR model, the main program does not know what information it needs, so we need to let it find some keywords in the recognition results. For example, "passport". When the string is successfully matched, the main program gets what it really needs.
2. Region of Interest(ROI)
If we are sure that the goal is always in the center or corner of the picture, we can filter out the results in the region by framing the region of interest, namely, effective results. Of course, we can also match a target detection model to "buckle" the passport part from the picture first.
3. Shape Detection
In many recognition result modules, if they have obvious shape differences, shape detection can be used to extract target information. In this case, we can find the passport number by targeting the result with the largest length or aspect ratio, as shown below:

Overall, the specific post-processing methods can be quite flexible. From a technical point of view, we can even consider using BP neural network to classify all text contents and make use of every message such as name and date of birth.
If you are interested in this application, we recommend OpenNCC IP4 to you for a try.
Credits
Related products















Leave your feedback...